
A/B Testing in Action: Best Practices, Pitfalls, and Lessons Learned
Don't become a Texas Sharpshooter!

I find A/B testing thrilling. When done correctly it allows you to iteratively improve your product, while ensuring that the changes you introduce resonate with your customers. Yet there are many pitfalls with a/b testing and it’s easy for product development teams to fall into common a/b testing traps.
In this edition of Shipping on Fridays I’m going to dive into a/b testing best practices and share 4 common pitfalls using a recent test I ran as a guide (all data obscured or fake).
A quick refresher: what is a/b testing:
A/B testing is a controlled experiment where the team develops a hypothesis based on a customer insight to change the customer experience in some meaningful way and then test that hypothesis by showing a % of the population the original (“A” or control) experience and showing a % of the population the test (“B” or experimental) experience. The team measures whether or not the B experience fulfills the hypothesis (thus becoming a “winner”).
Our real example: Introducing an Onboarding Wizard
Starting with an insight:
The genesis of any a/b test should be a customer insight. These emerge from a combination of quantitative research (looking at data which shows how customers use your product) and qualitative research (talking to those customers about their experience).
Our insight:
For my team, customer interviews revealed a painful truth: setting up a monitoring tool was extremely difficult for first time users. Customers said:
“There’s no step-by-step process on how this should work.”
“This took me hours”
“[I want] Something that takes your hand and guides you through the process of setting up”
Yet without a monitoring tool set up our product doesn’t work very well. Unsurprisingly, free trial customers without a monitoring tool converted more than 50% lower. Thus, if we could make it easier for customers to complete this set up we could alleviate a major pain point and increase customer conversion.
Developing a hypothesis:
Once you have that insight and have dug in to tease out the deep rooted customer problem, you can begin to develop a hypothesis and possible solutions. Every hypothesis should have 4 components:
Who you will impact
What you will build or change
The specific metric this change will impact (this is your success metric)
How much the specific metric will be moved
It’s crucial for your hypothesis to be specific in order to avoid common pitfalls.
⚠️Pitfall 1: The Texas Sharpshooter’s Fallacy
A common pitfall of a/b testing is what’s called the Texas Sharpshooter’s fallacy or moving the goal to fit the story of your test results. If you’ve ever heard someone say “the test wasn’t statistically significant, but it does improve X metric by Y%, so we rolled it out” - they’ve fallen prey to Texas Sharpshooters. When you do this you are shipping an experience you and your team prefer, but not necessarily an experience preferred by customers (see my post recounting a time I fell for this).
Our hypothesis:
Based on the insight we found about the difficulty of integrating monitoring tools we developed this hypothesis:
Making it easy for trialists to connect two of our top integrations will increase the % of trialists with actively used integrations, ultimately increasing % of 7 day Integration Incidents by 20% (from 12% to 14.5%)
Who: trialists
What: make it easy to connect two of our top integrations
Metric: % of trialists who actively use integrations within 7 days (called % 7 day Integration Incident)
How much: Increase by 20%
Testing the hypothesis:
Often when people think of testing they think the only way is to test is to create a design, turn that design into a software feature (via code) and ship that into production to get a reaction from customers. That’s another pitfall.
⚠️Pitfall 2: You have to test in prod
Testing in prod is expensive! Often it requires the team to prioritize non trivial code changes into a sprint, write that code, test that code, ship that code. Not to mention the PM, Design, Data, PMM and other cycles (such as communicating to leadership) that may be incurred. As a result, I’m a big proponent of starting off by testing the lowest fidelity concept as early as possible (once you have your insight and hypothesis). For instance, have customers walk through a design prototype of the control and test experiences and provide their reaction. This can be done in person or systemically using UserTesting.com (which can get you more scientific results). Testing early also helps ensure that the feature you prioritize for an in-product test (if you prioritize - be ruthless!) is actually a v3 or v4 of the original concept.
There’s another pitfall baked in here:
⚠️Pitfall 3: Everything must be tested
No! Not everything needs to end up as a test in production. As mentioned above, concepts should be tested in front of users, but not all of them need to become a/b tests in production. It’s tempting to build smaller changes (button colors, copy, etc) as simple a/b tests, but all of these tests have hidden costs. For instance, smaller changes might take a very long time to reach statistical significance, tying up your team (or at least a portion of their mental cycles) on changes that may have little to no impact.
Our test:
To improve the 7 day Integration Incident rate by 20% our team developed a new onboarding wizard to allow free trial customers to complete the integration set up directly in the onboarding flow. On the scale of a/b tests (from bug fixes to major features) this was a major feature.
Our testing process started internally, testing different iterations of the wizard with other product teams (especially the teams that managed those integrations and solutions consultants who helped customers set them up). Once we felt our design had passed the internal quality bar we then began to test designs with customers.
We made a habit of starting these conversations with open ended questions about how customers set up integrations and then moved to show them the new prototype. We recorded these meetings and iterated on the design along the way.
After passing these bars, we were ready for the team to begin development. Engineering had been involved from the beginning (in fact our engineers helped concept the design) and so they were already very familiar with the test and it’s two variants:
Setting the bar for Success:
Before implementing the test, it’s important to set the bar for success. Our original hypothesis provides our benchmark (must see a 20% improvement in 7 day Integration Incident rate). Now, it’s crucial to understand traffic and forecast when you should take test reads so that you don’t fall into Pitfall 4.
⚠️Pitfall 4: Calling a test too early
One of the most thrilling aspects of a/b testing is cheering on your experiment variant. It’s like a race. At Priceline I remember we used to watch hotel bookings come in real time to the different test variants - it was addictive. The thrill of being able to call a winner and posting your #winning announcement is so much fun. But to be a true winner, the experiment must reach statistical significance with a certain volume of traffic.
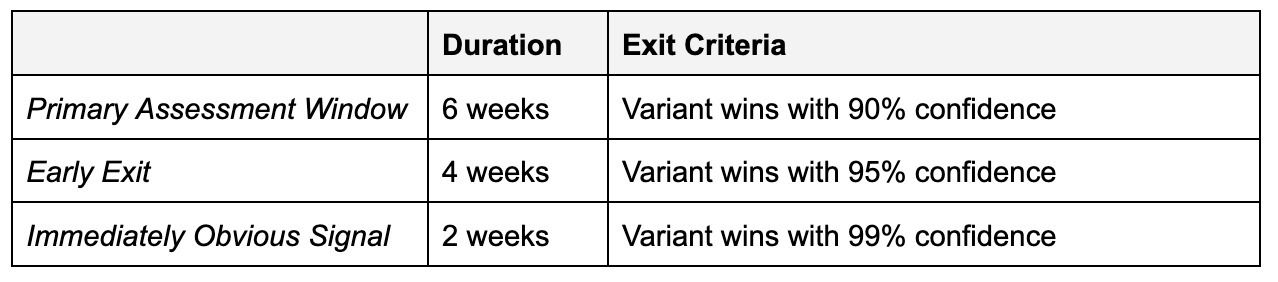
Our success bar:
For our test, I worked with our data scientist to define “exit” criteria or definitions based on our test volume for when we could call a winner:
Reading Results:
Lastly, it’s time to read the results and record the learnings. Ultimately a/b testing is all about learning and building upon what you learn. Whether or not the test is a “winner” will depend on the test’s performance against your success metric, but regardless you will learn (and often you can learn more from tests that fail).
When looking at the results of a test push yourself to go beyond your primary success metric. Work to uncover why the metric moved one way or another (or didn’t move at all). A few questions to consider:
What surprised you about the result?
What metrics moved that you didn’t expect to move?
How did the test impact your product engagement metrics?
How might the test impact other teams at the company or inform other teams about customer behavior?
Our results:
For our team, the test variant proved the hypothesis true, increasing the % of trialists who triggered incidents via an integration from 12% to 22%, a 90% increase! There were a few other key learnings we had:
Customers will complete seemingly difficult tasks in an onboarding flow if they see a possible benefit (and the tasks are discrete). The experiment added a significant number of steps to Onboarding (over 5!), yet over 75% of customers ended up completing the flow.
Customer who are introduced to integrations in Onboarding use them. Usage of the integrations did not wane after onboarding - it continued. This indicated our impact wasn’t localized, it lasted with customers.
Engaging onboarding reduces tourism. The experiment reduced the percent of tourists (trial accounts that take no action) by more than 20%.
Tips for your own A/B Testing
Relentlessly gather insights. Talk with customers regularly. Be up on your data and engagement metrics. Review competitive experiences. Talk with stakeholders about their observations.
Form hypotheses and hold yourself accountable to your success metric. Don’t become a Texas Sharpshooter.
Ruthlessly prioritize to ensure your test structure (effort) is aligned to your expected output (benefit). Remember there are lots of different ways to test from low effort (UserTesting.com prototypes) to high effort (in production a/b test).
Set parameters for success. Don’t call a test too early and be caught with a false positive. Hold yourself and your team accountable to stat sig results.
Analyze your results. A/B testing is about learning. A/B testing is about learning. Dig into what happened, write about it, share the writing.